PC Plus HelpDesk - issue 213
This month, Paul Grosse gives you more insight into
some of the topics dealt with in HelpDesk and HelpDesk
Extra
|
 |
HelpDesk
Linux file and directory permissionsLinux divides users into three categories: Those that own a resource (the user); those that are in the same group as the user; and everybody else. Permissions for file and directory resources are read, write and execute (or, for a directory, show entries, write entries and enter the directory, respectively).
These have the same purpose though and when you do use
shell commands that change these attributes, you will
need to understand not only what they mean but how to
generate the numbers. If you want to change these from the command line, you will need to express the desired values as numbers by dividing them up into octals (as opposed to octets - an octal has three binary digits and has a value between 0 and 7 (ie 8 possible values) whereas an octet has eight binary digits and has a value between 0 and 255 - these being seen in IP addresses and subnet masks et cetera). Each octal follows the following pattern ...
... with the first being for the owner, the second being for the group and the third being for everybody else. Thus, if you wanted a files' owner to have read, write and execute rights, the rest of the group only to be able to read it and execute it and everybody else only to be able to execute it, you would want to set the attributes to -rwxr-x--x and you would use the value 751 as taken from the table above. You will notice that there are three other options on the dialogue: Set User ID; Group ID and Sticky. If you want to change the owner or group that a file belongs to, you can use these. Sticky is a bit confusing as it is implemented in different ways according to which operating system you are using. If you want to make a file sticky, in Linux it will (most likely) be ignored. A directory that is sticky such as /tmp, can have other user's files in it and only the file's owner or root can delete it. |
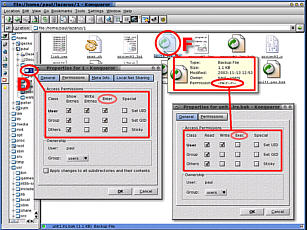 In the GUI - KDE,
Gnome, et cetera - the user is insulated from the command
line and is instead presented with the dialogue boxes in
the screenshot on the right.
In the GUI - KDE,
Gnome, et cetera - the user is insulated from the command
line and is instead presented with the dialogue boxes in
the screenshot on the right.Printer Drivers - GodelGodel's incompleteness theorem works on the principle that if a system is sufficiently complex, it is not possible to work out all of the possible ways of combining all of the elements of that system. A result of this is that no matter how well you test a piece of software (or other equipment), there will be a set of circumstances when it will not work or, will not work as predicted. In other words, if you find a set of commands that hang up your printer, whilst it is possible to re-write the driver, you can guarantee that there will be another combination of commands that will have the same effect - either from code introduced in the update or an unresolved vulnerability in the older parts of the code that, due to its complexity, could not be tested adequately. This extends to other areas of computing life as well (if not all areas of life). If you write a computer programming language that has sufficient complexity (possibly just being able to put various combinations of only a few commands together but in an unlimited way), there will be a program that will not work - not through bad programming but because it breaks the compiler. Another area this is seen is with Sylvia Laycock's experiences regarding the compatibility of her broadband ISP's USB driver with her existing (already proven, working) system based on Windows 98 and Internet Explorer 6.0. It needn't be the program specifically as it could be down to which processor you use, the mother board, something about a cable, the fact that you use a network printer server, font-size, -type, -colour, particular wordprocessor/ DTP/ spreadsheet ..., operating system and so on. As people test programs by using them and bugs are reported, the more common circumstances that cause problems can be written out of the code so that only less likely combinations cause the effect. The upshot of this is that you should keep your drivers up-to-date and don't expect them to be perfect. You can look for drivers on your vendor's website and if you want to see if anybody else has been having similar problems, a good place to start is http://www.google.com/ . |
Black ink in colour printingTheoretical yellow (Y), magenta (M) and cyan (C) will absorb all of the light when they are mixed together therefore theoretical YMC can be mixed together to make black. However if we try this in the real world, we get different results...
Apart from the fact that real inks do not absorb all of and only the wavelengths of light that they are supposed to, there is the fact of economy which is also related to a practicality - if you use black instead of the redundant quantities of yellow, magenta and cyan, you are also cutting down on the quantity of solvent that has to evaporate before the page can be touched.
As you can see, the total amount of ink is reduced
dramatically.
You can try this out for yourself by saving the four images (in Internet Explorer, right-click and then save the image or you can take them from the SuperDisc using Windows Explorer) and then, using a suitable image processor, superimpose them using a subtractive system (ie, you start off with white and take the colours away from it) and you will get the full colour image built up in front of your eyes. |










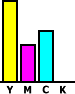 As the
intention, where all three colours are used, is to create
black, then why not use black instead? On the right, we
see a fairly desaturated colour with all three inks in
use.
As the
intention, where all three colours are used, is to create
black, then why not use black instead? On the right, we
see a fairly desaturated colour with all three inks in
use. If we take away the
magenta completely (because, in this case, it is the
smallest of the three) and then take away the same
amounts of the other three inks, we end up with a
modified mixture of inks as those on the right for our
example.
If we take away the
magenta completely (because, in this case, it is the
smallest of the three) and then take away the same
amounts of the other three inks, we end up with a
modified mixture of inks as those on the right for our
example.







XP Task Manager Revealed
Apart from turning off the always on top option in the Options menu, the view menu is quite useful and this changes according to which tab you have selected. With the Processes tab selected, View allows you to select which columns you want to see and Options allows you to see 16 bit tasks as well. With the Performance tab selected, View allows you to see the Kernel Times so moving the mouse around, selecting other programs, menus and so on produce a response. With the Networking tab selected, you can also see the bytes sent and received and if you have two interface cards, they will be displayed as separate graphs. If you double click on the graph, it will occupy all of the window and can be moved anywhere on the screen just by dragging with any part of the window - although it won't let you leave it with the top off the screen so that if you clicked it back, you would not be able to drag it again. |
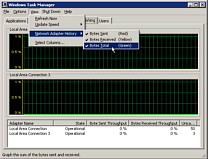 If you
press [Ctrl]+[Alt]+[Del] in Windows XP, you will get a
program called Task Manager. Whilst this lets you know
about which programs you are running and allows you to
shut them down, as does the Close Program program in
Windows 98, it will also tell you a few things about the
system.
If you
press [Ctrl]+[Alt]+[Del] in Windows XP, you will get a
program called Task Manager. Whilst this lets you know
about which programs you are running and allows you to
shut them down, as does the Close Program program in
Windows 98, it will also tell you a few things about the
system.Installing and removing programs in Linux
In YaST, if you select a program to remove and it provides components that are used by other programs, instead of giving you a little message during the removal process letting you know that there are files that might be used by other programs, YaST will let you know in advance that this will impact upon other programs and, as you can see in the screenshot, gives you several options of what to do - emacs is chosen here only to illustrate the point. |
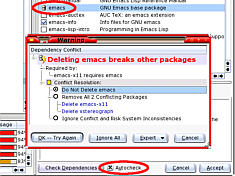 If you decide to
clean up your system, any RPMs that you have installed
will be registered with YaST if you installed them using
YaST - if you select an RPM in Konqueror, it will
automatically give you the option to install it with
YaST.
If you decide to
clean up your system, any RPMs that you have installed
will be registered with YaST if you installed them using
YaST - if you select an RPM in Konqueror, it will
automatically give you the option to install it with
YaST.XP's bloated interface
You can see that there is only one pixel in it but that is all that it takes when inputting numbers. Allowing the user to input their own information is possibly one of the most dangerous things a programmer can allow a user to do because it involves checking that they have not done anything stupid - most people will not but some people will and you have to cater for all. Filtering out unwanted keystrokes is one problem and an easy way to do it is to make sure that only numbers are input and then, make sure that there are not too many of them. Here, a whole number from 0 to 255 inclusive is required so the only allowed characters are 0123456789. 255 is only three characters long so one way of checking that an extra digit is not typed is to look at the length of the text in the box and compare it with the box. In Windows XP, adding a third character takes it one pixel over the limit therefore the highest number you can type in is 99 and only 100 to 255 (156 values) has to rely upon the spinner. This is lucky in a way because you can imagine a situation where the box has numbers from 0 to 65,535 and you can only get 9,999 in. The solution to this problem is to use the Classic interface which, apart from not giving you a migraine, uses less resources as well. |
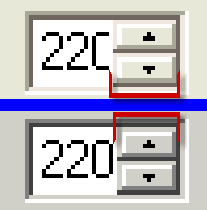 The images
on the right come from the same program but under the
Windows XP interface on the top and the Classic (Windows
98) interface at the bottom.
The images
on the right come from the same program but under the
Windows XP interface on the top and the Classic (Windows
98) interface at the bottom.Images - bitmaps to ASCII
You can do the same now with any bitmap type image using a program called ASCII Pic available from http://www.ykwong.com/ . First, you need to get an image - here the Mona Lisa
but you can find images of any artwork on gallery
websites. The reason for needing to do this in the first place is that pixels on the screen are usually one unit wide by one unit high - the dpi is the same up and across. Fonts however do not have a 1:1 aspect ratio so you will have to compensate for this by squashing the image. Another thing to remember is that different mono-spaced fonts have different vertical spacings so the font itself will change things. Just in case you were wondering, this will only work if you use a mono-spaced font such as Courier New and so on. You might find that you image editor does not support changing the aspect ratio of an image as well as using smart sizing or blending for the pixels so you could change the aspect ratio whilst the image is large and then reduce it in size in two steps. You might also want to change it to monochrome here as well.
Once you have done this, go back to Process and hit
the Process button
Click here to see the Mona Lisa Text file monalisa.txt in a new window. Things like this can make excellent footers for emails although I would recommend cutting the size down so that it was no bigger than 70 characters wide by possibly 8 line high. |
 Several decades ago,
there was a file that you could print out on your
teletype that produced a picture of the Mona Lisa. In a
totally non-graphical world - as far as teletypes were
concerned - this was quite novel.
Several decades ago,
there was a file that you could print out on your
teletype that produced a picture of the Mona Lisa. In a
totally non-graphical world - as far as teletypes were
concerned - this was quite novel. Next, load the images
into your favourite image processing program and change
the aspect ratio slightly - you might find that you need
to experiment with this to get it right.
Next, load the images
into your favourite image processing program and change
the aspect ratio slightly - you might find that you need
to experiment with this to get it right. Then, load
up the processed image into ASCII Pic and specify an
output file
Then, load
up the processed image into ASCII Pic and specify an
output file If you click along
the tabs, you will be able to see the image on the
process tab.
If you click along
the tabs, you will be able to see the image on the
process tab.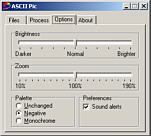 On the Options tab,
you will be able to change the brightness and zoom. In
addition to this, you can leave the palette unchanged or
elect to use a negative palette.
On the Options tab,
you will be able to change the brightness and zoom. In
addition to this, you can leave the palette unchanged or
elect to use a negative palette. If you selected
'negative', you will get output which, if processed like
this (green text on a black background) will look like
the display output from a monochrome VDU.
If you selected
'negative', you will get output which, if processed like
this (green text on a black background) will look like
the display output from a monochrome VDU. If you leave it
unchanged, you will get text like this.
If you leave it
unchanged, you will get text like this.HelpDesk Extra
Camera and image capturing software
However, even though these cameras are not
weather-proof and therefore are unsuitable for outside
use, they do have the advantage that with one, you can
try out all of this project at virtually no extra cost.
Of course, these cameras do not have their own ftp server
or even a network connection so you will need to obtain a
program that can save jpeg format images (.jpg files) to
disk at regular intervals
If you are going to use coloured backgrounds for your
text, use spaces at the beginning and the end so that the
text doesn't come into direct contact with the image
behind - this stops letters with long straight verticals
becoming unclear.
|
||||||||||||||||||||||||||||||
 If you are using a
normal USB camera like the one on the right, you will
need to be within 5 metres of a computer and whatever you
are looking at should be fairly well illuminated.
If you are using a
normal USB camera like the one on the right, you will
need to be within 5 metres of a computer and whatever you
are looking at should be fairly well illuminated.  For this, I used Bill
Oatman's SpyCam shareware program which is a free
download from www.getspycam.com. Once it is installed,
its main menu is accessible from the system tray by
right-clicking the SC logo. The logo also tells you of
its status by using different colours:
For this, I used Bill
Oatman's SpyCam shareware program which is a free
download from www.getspycam.com. Once it is installed,
its main menu is accessible from the system tray by
right-clicking the SC logo. The logo also tells you of
its status by using different colours: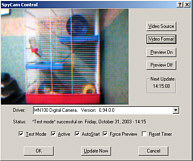 Yellow
is 'active',
Yellow
is 'active',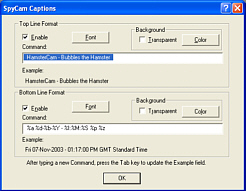 of the program is covered in the magazine
but on the captions page, there are a number of codes
that are used to get SpyCam to insert the date and time
in the image. The main ones are:
of the program is covered in the magazine
but on the captions page, there are a number of codes
that are used to get SpyCam to insert the date and time
in the image. The main ones are: When you have
finished your evaluation - assuming that you want to use
the system for outside monitoring rather than keeping an
eye on your pet hamster at home or your cockroach project
at university (
When you have
finished your evaluation - assuming that you want to use
the system for outside monitoring rather than keeping an
eye on your pet hamster at home or your cockroach project
at university ( This is like your
firewall or UPS in that it is configured remotely so if
it is snowing, you don't have to get cold and wet. Using
a special powered LAN lead, they have a range of up to
100 metres and if you use are thinking really extreme,
they can be solar or wind powered and use a radio link.
This is like your
firewall or UPS in that it is configured remotely so if
it is snowing, you don't have to get cold and wet. Using
a special powered LAN lead, they have a range of up to
100 metres and if you use are thinking really extreme,
they can be solar or wind powered and use a radio link.Web page designIn order to get images to download onto a user's browser, you can use JavaScript but this means that this has to be enabled on the user's browser. There is no justification for forcing the user population to compromise its security by allowing scripts to run if it is not entirely necessary. So, by far the easiest and most secure way of pulling images off a server without doing this is to use a meta tag that has been supported since Netscape 2 and IE 2. RefreshThe refresh tag in the head of an html page will make the page that is defined in the tag load after the specified delay in seconds. It looks like this... <meta http-equiv="REFRESH" content="60;URL=wc60.html"> Like other meta tags, it defines the function ("refresh") and then has content which, in this case, has two parts: the delay time (60) and the URL to load (wc60.html). Note that the content encloses the information in quotes and separates the variables with semicolons. In this case, the URL points to the same file (the line is taken from one of the sample files on this month's SuperDisc) so that it reloads although there is no reason why you should not have it point at another file, such as if you were displaying a selection of shots. Iframe
Iframes have attributes similar to image files and
this is the line taken from the index.html file on this
month's SuperDisc... <IFRAME WIDTH=360 HEIGHT=296 SRC="wc60.html" marginwidth="0" marginheight="0" hspace="0" vspace="0" frameborder="0" scrolling="no"></IFRAME> Like the image file tag, it has width and height values along with a source. Iframes will appear with a border that makes it look inset into the page and if you want it to look part of the page instead, you can remove this by specifying frameborder="0". Also, if the page is bigger than the available space in the frame, scrollbars will appear so you can prevent these by using scrolling="no". Look at the source code for the main page and the iframe pages that fit in it to see how the image fits, leaving a border around it with the correct colour.
If you are on a faster connection, clicking on the image (because we have made it a hotlink to another page) loads up the 20 second page which now downloads every other 10 second image. Clicking on the image again takes the iframe page to a 10 second page, loading up every image. In the diagram, the automatic loadings are in blue and the interactive ones are in red. Clearly, the browser does not know when the image is saved to the disk on the server but this setup means that you have a time delay of no longer than 10 seconds plus the download time. The advantages of doing it this way are that the user does not have to use any scripting and there is no need to keep any connections open as everything is requested by the browser. |
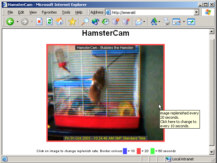 If your web page is
large (in terms of file size) in comparison to the size
of the image, it would be better to have a very small
page that downloads instead so that the larger page is
static. To do this, you can use an iframe which provides
a smaller browser window within which the refreshing
window sits, leaving the rest of the page alone.
If your web page is
large (in terms of file size) in comparison to the size
of the image, it would be better to have a very small
page that downloads instead so that the larger page is
static. To do this, you can use an iframe which provides
a smaller browser window within which the refreshing
window sits, leaving the rest of the page alone.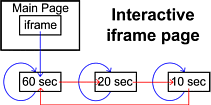 Using a combination
of an iframe in the main page and refresh tags in the
smaller page, the main page loads and automatically loads
the 60 second reloading page, along with its image. After
60 seconds, just the small page reloads, along with the
new image. This allows plenty of time for people with
slower connections, such as if you were at a friend's
house and he only had a 33.6kbps dial-up account.
Using a combination
of an iframe in the main page and refresh tags in the
smaller page, the main page loads and automatically loads
the 60 second reloading page, along with its image. After
60 seconds, just the small page reloads, along with the
new image. This allows plenty of time for people with
slower connections, such as if you were at a friend's
house and he only had a 33.6kbps dial-up account.Site contentHtml and image filesClearly, you need to have any html files and your current image file on your site but if you want other people visiting it, there are some things you need to do: If you are using your own site, you will probably not have a very easy to remember and very long URL that is there for your ISP's benefit and not yours. Also, you might find that it changes at the whim of your ISP or if your site is down long enough for your DHCP lease to run out. So, if you are in these circumstances, you will probably need to have at least a link from the website that your ISP has given you as this will be static and if your IP address changes, you can update this, only missing a small amount of traffic. Favicon.ico
Randy's Icon Editor (right) is freeware (from ranfo.com/iconedit.html
) and will produce standard icons in .ico format that
will be suitable for any browser. Here, you can see it
with the hamstercam icon.
Robots.txtIf your site is linked to from a permanent address or one that has already been listed on a search engine (or in some cases, merely existing on the Internet is enough), it may well be probed by a search engine spider program so that it can be listed. If there are areas of your site that are linked to but you don't want the search engine to go to (such activity can cause trouble such as voting and so on), you can list these directories in a standard text file called "robots.txt". This has the standard format below with REMmed out lines starting with a hash mark (#). The first line that is read specifies the search engine - in this case, all of them - and the following lines specify where it is not allowed to go. # robots.txt for http://[your.web.page]/ # 03.11.2003 User-agent: * Disallow: /cgi-bin/ Disallow: /bigsecrets/ Disallow: /maillist/ Disallow: /images/ Disallow: /css/ If you want to block a specific spider, you should do so before the wildcard line thus... # robots.txt for http://[your.web.page]/ # 03.11.2003 User-agent: [robotname1] Disallow: / User-agent: * Disallow: /cgi-bin/ Disallow: /bigsecrets/ ... and so on Of course, there is no way that you can guarantee that every search engine will follow this standard and it could be used to glean information about your directory structure so if you have a private directory, the best thing to do is to password protect it as simply not mentioning it will not stop a search engine's spider program from finding it. |
 Some people will want
to add your page to their favourites list and when this
happens, Internet Explorer looks in the site's root for a
file called "favicon.ico" so you will need one
of them. You will also find it useful yourself as we
shall see when we start looking at the access log.
Some people will want
to add your page to their favourites list and when this
happens, Internet Explorer looks in the site's root for a
file called "favicon.ico" so you will need one
of them. You will also find it useful yourself as we
shall see when we start looking at the access log.


Web ServerBefore you install your web server, make sure that there is nothing already on port 80. You can check this out by opening up a browser window and typing http://127.0.0.1/ in the address bar. If you get "The page cannot be displayed", you are on to a winner. If you have something already there such as a UPS, you should probably have to configure that to use a different port instead (remembering to redirect any pages that use that to that different port such as http://johns-server:8080/ for port 8080. With port 80 clear (this makes things easier later on), you can install Apache. Stopping and starting
Configuration filehttpd.conf lets Apache know what you want it to do (or at least what you have told it to do which might be a different thing). Some things it needs to know are:
Most of these remain set to their defaults although server root and document root need to be specified (although on mine, the server root was already correct). Access control
You will need to create at least a passwords file and, if you want access to be available to a group of people, a groups file as well. It is wise to have these somewhere other than in the downloadable part of the directories so, on the server root, create a new directory called 'passwd'. In it, you will need to create a passwords file and, if you are using groups, a groups file as well. To create a new passwords file, go into the DOS command line and CD to the Apache root (do this by typing "CD C:\Program Files\Apache Group\Apache2") and then type... bin\htpasswd -cb passwd\passwords username userpassword ie, bin\htpasswd -[create new file][take password from command line] [user name] [their password] To add another password to the same file, leave out the c, ie bin\htpasswd -b passwd\passwords user2name user2password If you want a group of people to access the directory, create a text file called 'groups' and store that in the passwd directory (it doesn't have to be there but it makes sense) and in that file, create a new line for each group as follows... secview: jbloggs hpew fpeters where secview is the name of the group (it doesn't matter what this is as long as it means something to the person configuring the web server) and jbloggs and so on are space-delineated user names, ie, the users that will have access to the given resources. There are two ways of introducing the familiar password requirement into the proceedings: the httpd.conf file and .htaccess files. If you haven't got access to the conf file, you can use the .htaccess file which is a plaintext file stored in the directory you want to protect or change the access configuration of. The file name does begin with a dot because on UNIX/Linus systems, this makes it a hidden file. If you don't want to change this standard, you can create such a file by typing in the content into notepad and then saving it as ".htaccess" (no quotes). If you leave the 'save as file type' as 'Text Documents (*.txt)' the file you will save will be '.htaccess.txt' and if you try to change this in Windows Explorer, it will generate an error along the lines of: you cannot save a file without a file name' because it views '.htaccess' as a file extension. To get around this problem should you encounter it, change the 'Save as type' to 'All Files'. If you have problems with the .htaccess file and think that it might be down to the fact that it does start with a dot, you can use a file with a different name and specify that in the httpd.conf file. The easiest way to find anything specific in the file is to search for - in this case - .htaccess and then take the appropriate action. The content of the .htaccess file is the same as what you would put into the httpd.conf file which, being somewhere other than the tree of directories that users have internet access to, is safer. You can stop people who have gained access to a directory from downloading your .htaccess and .htpasswd files by including the lines... <Files ~ "^.ht">
Order allow,deny
Deny from all
</Files>
in the httpd.conf file (this is normally in there by default but it is worth checking it out just in case). Remember to block access to the alternative name that you use if you decide to use something other than .htaccess as the file name (keep to the httpd.conf file if possible as it is all simpler). The advantage of using .htaccess files is that you can change them without having to restart Apache. However, if you have access to the httpd.conf file, you are better off putting the information in that. In a Directory section, you can implement password access using the following lines (which are specific for that directory and all directories below it in the tree unless there is another directive)... <Directory "G:/WebRoot/secrets"> AllowOverride AuthConfig Options Indexes FollowSymLinks Order allow,deny AuthType Basic AuthName "Secrets Directory" AuthUserFile "CD C:/Program Files/Apache Group/Apache2/passwd/passwords" AuthGroupFile "CD C:/Program Files/Apache Group/Apache2/passwd/groups" Require group secview Satisfy Any </Directory> Note:
When one of the users attempts to gain access to this directory, they will be presented with the passwords-required dialogue in their browser and the AuthName line's argument (in this case: "Secrets Directory") will be displayed. Their user name will also be recorded in the access log. Logs and traffic analysis
Webalizer (on the right) has breakdowns into an
overall summary of the last twelve months and clicking on
each of these in the table at the bottom takes you to the
monthly breakdowns.
|
 There are ports of
Apache to many operating systems, including Windows. The
program (httpd) runs as a service in the background and
would normally be stopped and started from the command
line. The program automatically starts when you load up
Windows so why would you need to stop and start it? The
answer is that if you make changes to the configuration
file (httpd.conf), you need to restart the program for
the changes to take effect.
There are ports of
Apache to many operating systems, including Windows. The
program (httpd) runs as a service in the background and
would normally be stopped and started from the command
line. The program automatically starts when you load up
Windows so why would you need to stop and start it? The
answer is that if you make changes to the configuration
file (httpd.conf), you need to restart the program for
the changes to take effect. If you have set this
system up so that you can view security cameras, you will
want to prevent other users from accessing your images
because these could reveal weaknesses in your system such
as blind-spots, poor lighting conditions and so on.
If you have set this
system up so that you can view security cameras, you will
want to prevent other users from accessing your images
because these could reveal weaknesses in your system such
as blind-spots, poor lighting conditions and so on. There are a number of
access log analyser programs but the one that (arguably -
because of the basic lack of significantly sized samples)
is used the most is webalizer -
There are a number of
access log analyser programs but the one that (arguably -
because of the basic lack of significantly sized samples)
is used the most is webalizer - 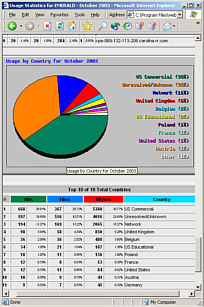 Monthly graphs and
stats include users (so you can see who has been
accessing your password protected directories), browser
types and OS's, countries of origin, hits, files, pages
and so on, day-of-the-month and hour-of-the-day
breakdowns, URLs visited, entry and exit points and so
on.
Monthly graphs and
stats include users (so you can see who has been
accessing your password protected directories), browser
types and OS's, countries of origin, hits, files, pages
and so on, day-of-the-month and hour-of-the-day
breakdowns, URLs visited, entry and exit points and so
on.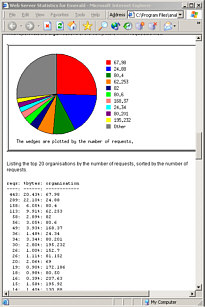 Analog's output is
similar with graphs and statistics and the intention is
clear with both programs that you can - if you really
want to - show users how well your website is doing.
Analog's output is
similar with graphs and statistics and the intention is
clear with both programs that you can - if you really
want to - show users how well your website is doing.Firewall ConfigurationYour firewall needs to be configured so that inbound traffic on port 80 is sent only to the machine with the server on it. If you have NAT enabled on your firewall, this is done fairly easily by setting up a new rule something along the lines of:
That should take all inbound traffic directed to your firewall on port 80 and send it to host 192.168.243.18 on your LAN, here set to operate between certain times on certain days although you can have it open all of the time if you wish. |
AttacksOne attack - merely to glean more information about your server so that the attacker knows what they are fighting - is to send a request for a file that does not exist. This will make the server send out an error 404 page which will usually contain information about the server version, OS and so on. You can cut this information down to a minimum by changing a line in httpd.conf as follows... ServerTokens Full should be changed to... ServerTokens Prod You can change error responses to whatever you like, either plain text, or a local or external re-direct as follows (use a variation on one of them - for each error you should specify only one)... ErrorDocument 404 "Sorry, we haven't got one of those." ErrorDocument 404 errordocs/404.html ErrorDocument 404 http://www.some_site.com/some_page.html I cannot stress enough the importance of not having a line that generates an error document for code 200 (successful) as this would be generated each time a page was downloaded successfully and it itself would generate another code 200 (as well as the page again which would be retransmitted but for this time ...) and so on. It would be especially ironic if you had a directive for a document for code 200 but did not have a document that it referred to although this would not run away. Another one to avoid is 304 - unchanged. There is a full list of these codes on the Internet. Of course, being a web page, you can make the error document as simple or as complicated as you like and do anything that any other web page can do on its own (remember that scripts will be blocked by anybody with any security sense so you are limited to reloading pages, playing sound files, having enormous graphics, overloading their machine by having an enormous web page that stretches miles down below the bottom of their desktop and so on. Look at the examples here on the SuperDisc for a Plain, Fancy and Misleading 404 error page You will also find a number of attacks on IIS servers. These often have a number of requests that fail (because they are looking at the wrong server-type for a start) that can happen over a short time. If your access log file doesn't state what agent (browser) type is used, it is probably an Internet worm, looking for a new host. There are several things you can do when you come across a line in your access log that tells you of one of these attacks:
To get somebody's domain name from their IP address, use nslookup (it will work the other way around as well) or, if you haven't got nslookup on your system, go into www.google.com and use "reverse dns lookup" (no quotes) as the search string. nslookup xxx.xxx.xxx.xxx where xxx.xxx.xxx.xxx is their IP address. In Linux, you can try... host xxx.xxx.xxx.xxx instead as nslookup is deprecated. Got a friendly domain nameIf you get a positive identity, use the end of the name to find their ISP eg: userip12-23-34-45.stack12.derby.ispname.com is returned go into www.google.com and type in the last two parts (ispname.com) and see what you get. If you are lucky, you will get an ISP and searching through their website might reveal an email address that you can use. If you cannot get very far with that, try using whois... whois ispname.com and that will tell you who is responsible for the site. If whois is not on your machine, you can download a copy from the Internet - there are zips of whois for a variety of systems as well as the source code if you want to compile your own. Look at Phil Ottewell's site http://www.pottsoft.com/home/pds/pds.html for a copy that has executables for Windows NT, 2000, XP, 98, 95, Intel/Alpha and the source with a make file for Windows NT and OpenVMS VAX or Alpha. For some interesting information about whois, have a look at rfc954 ( http://www.faqs.org/rfcs/rfc954.html ). Supply the line(s) from your access log to the people responsible and they can start doing something about it. No friendly domain nameIf you don't get any luck getting a friendly domain name from nslookup/ host, try using the following to get the domain name:
With the domain name and the contact, supply the line(s) from your access log to the people responsible and they can start doing something about it. Honey potsWhen you start looking at your log file, you will notice that there are a lot of people out there with too much time on their hands, scanning IP addresses for port 80 and then trying to see if there is an unpatched IIS server vulnerability. As you are running Apache, they are useless but all of them are logged. You will see that amongst the various buffer overflow attacks, some people try to attack specific files and if you wish, you can generate files with these names and put them in the directories in which they are looking for them. On the SuperDisc example, you will see a number of such files. One error 404 attack comes (apparently) from a program that requests a file called 'sumthin'. If you provide it with such a file, the useful information is not found. If it is a person doing this, you can make them think about what they are doing if they are doing it from a browser. The file, without an extension, is an html file and as their browser requested it from a web server, it will display it. On the SuperDisc, the file 'sumthin' contains...
and renders like this...
Which might be enough to stop the odd one from entering a life of cybercrime, especially when they get the feedback from their ISP. Another attack is looking for scripts/nsiislog.dll. If you have a file for them to download - again, this is an html file - it might just have the desired effect. On the SuperDisc, you will see such a file but called nsiislog.dll.txt. You can copy this across into your scripts log for them to find if you want to but you must remove the .txt extension. This extension is there because if you just dragged it across and dropped it into a directory, your system might try to install it for you. Providing attackers with files they are looking for might not be what you want and there is certainly an argument for not doing this. However, if you think that letting them know that they are being observed might have a positive outcome (not necessarily for you but someone else that might get hacked if they carry on and get good at it) then you can have a go. |