PC Plus HelpDesk - issue 224
This month, Paul Grosse gives you more insight into
some of the topics dealt with in HelpDesk and HelpDesk
Extra
|
 |
HelpDesk
Windows Media Player Skins buttonWindows Media Player has with it a number of skins so that you can (presumably) improve your experience whilst being entertained by whatever it is you are listening to (or watching). Anyway, you can load skins...
|
 The
one on the right is typical. Clearly, there is no
button to select another skin so, our mission is
to locate the little blighter.
The
one on the right is typical. Clearly, there is no
button to select another skin so, our mission is
to locate the little blighter. This
is our first step towards Skin-Nirvana...
This
is our first step towards Skin-Nirvana... When
you hover your mouse over it, it lights up and
you get a message telling you what it is supposed
to mean.
When
you hover your mouse over it, it lights up and
you get a message telling you what it is supposed
to mean.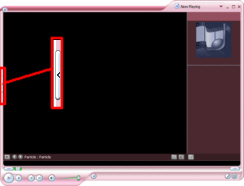 Once
you have clicked on it, you get back to the
'normal' skin but still no button.
Once
you have clicked on it, you get back to the
'normal' skin but still no button. You
get your list from where you can choose another
delightful skin.
You
get your list from where you can choose another
delightful skin. One
bug that SP2 has not cured is that of
jagged-edged windows. As you can see here,
shallow curves produce them in abundance.
One
bug that SP2 has not cured is that of
jagged-edged windows. As you can see here,
shallow curves produce them in abundance.Linux Directory VisualisationsIf you select the text directory listing in the KDE file manager (Konqueror), you will get the size of the directory file for each directory as opposed to the size of the contents of each directory. This actually makes sense because most of the time, you are not interested in the directory other than the fact that it is a directory and that you can click on it to look at its contents. However, there are some times when you would like to know just how much space a particular directory is taking up - say, if you want to find out which user account is taking up all of your hard drive (all you want to do is save a few smallish images but somebody has taken all 25GB with something, leaving you with no room and you want to know who).
|
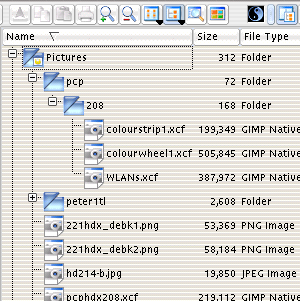 In the screenshot on the right, you
can see that the pictures/pcp/208 directory has
168 bytes in it. That is because the directory
you are looking at is just effectively a file
that is 168 bytes long - it contains all of the
important information that the system needs to
locate its contents and look after it.
In the screenshot on the right, you
can see that the pictures/pcp/208 directory has
168 bytes in it. That is because the directory
you are looking at is just effectively a file
that is 168 bytes long - it contains all of the
important information that the system needs to
locate its contents and look after it.
 In KDE 3.2, we saw a new button...
In KDE 3.2, we saw a new button...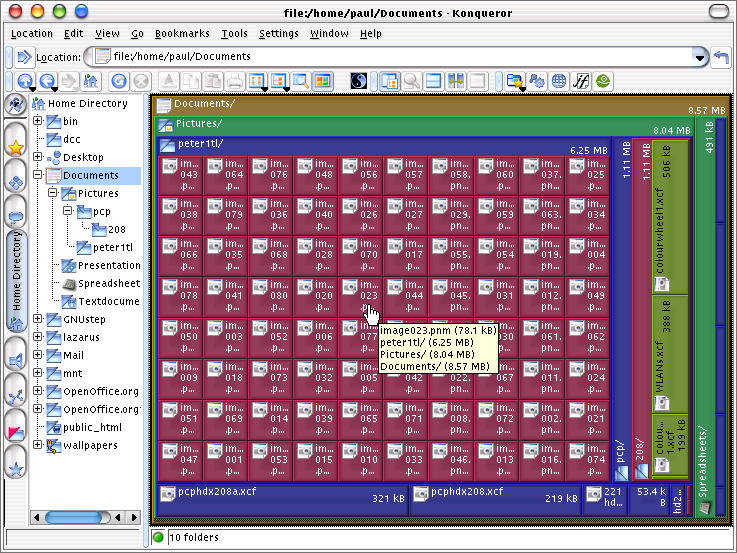
 Just hovering the mouse over a file
with give you the data that you normally get -
this is part of Konqueror so whatever Konqueror
would normally do in any other display mode, gets
done here as well.
Just hovering the mouse over a file
with give you the data that you normally get -
this is part of Konqueror so whatever Konqueror
would normally do in any other display mode, gets
done here as well.Perl BooksPerl makes many jobs easy and the rest of them at least possible. To support Perl, there is a lot of material on the Internet but when you are away from your computer, you can't beat a good book. The following are six good books (three in hard copy and you will find out where the other three are as you read on). Prices - With regard to pricing, I'll quote the US Dollar prices that are on the books. The price in GB Pounds should match (within reason) the conversion for the currency but beware (I've seen different values for this). When looking around my local book stores, I found that one copy of the Perl Cookbook was on sale for £49.95. The US price was $49.95 and when I called my contact at O'Reilly, to put it politely, she conveyed the concept of dissatisfaction with the price and informed me that she would telephone them about it. A few days later, I went into that book shop (which shall remain nameless) and found that the offending price label had been removed, leaving behind only part of the label. I checked with their sales personnel and it was confirmed that the price was (now) £35.50 (including VAT). Some places will charge more, some will charge less, if you are buying it for business, you can recover the VAT, if you are a student, you will get various levels of discount and so on - I give the USD prices because they are printed on the book - the GBP prices are not. Pages - the number of pages varies from information source to information source. I have the copies in my hand so I'll just say:
That should give you an idea. I was toying with giving you the weight as well but that was going a bit too far I thought :-)
|
 Learning Perl is
suitable for (although by no means limited to) a
beginner to the language, although it is always
an advantage to have another programming language
under your belt to start with. The book assumes
that you are already familiar with basic
programming concepts such as variables, arrays,
input/output concepts and program flow control
structures and, not unreasonably, how to edit
text in your favourite text editor.
Learning Perl is
suitable for (although by no means limited to) a
beginner to the language, although it is always
an advantage to have another programming language
under your belt to start with. The book assumes
that you are already familiar with basic
programming concepts such as variables, arrays,
input/output concepts and program flow control
structures and, not unreasonably, how to edit
text in your favourite text editor. Perl in a Nutshell
provides (very) brief descriptions of just about
everything. There are examples but they are few
and far between - if you are not familiar with at
least the basics of Perl (as you will have
learned them from Learning Perl (above)) you will
find it difficult to get very far with this book.
Perl in a Nutshell
provides (very) brief descriptions of just about
everything. There are examples but they are few
and far between - if you are not familiar with at
least the basics of Perl (as you will have
learned them from Learning Perl (above)) you will
find it difficult to get very far with this book. The Perl Cookbook
provides hundreds of ready-made programs/snippets
which you can copy into your own code either
directly or with only minor modifications. The
book covers everything from strings, numbers,
date/times, arrays, hashes and pattern matching
to files and directories, subroutines, classes,
objects and ties to database access,
interactivity, mod_perl and XML (and much in
between and beyond).
The Perl Cookbook
provides hundreds of ready-made programs/snippets
which you can copy into your own code either
directly or with only minor modifications. The
book covers everything from strings, numbers,
date/times, arrays, hashes and pattern matching
to files and directories, subroutines, classes,
objects and ties to database access,
interactivity, mod_perl and XML (and much in
between and beyond). The Perl CD Bookshelf
4.0 is six books on one CD: The three books
already listed above plus: Programming Perl;
Learning Perl Objects, References and Modules;
and, Mastering Regular Expressions.
The Perl CD Bookshelf
4.0 is six books on one CD: The three books
already listed above plus: Programming Perl;
Learning Perl Objects, References and Modules;
and, Mastering Regular Expressions.HelpDesk Extra
Getting PerlPerl is available for many platforms. If you have not already got it on your computer (your PC or some other computer that you work on), the place to start looking is at http://www.cpan.org/ports/ . If you are curious as to just how cross-platform Perl is (and therefore how transferable and valuable learning the Perl language is), these are some known ports:
|
The scenarioYou have a firewall with all ports closed except for port 80 (http) port 25 (smtp) and port 110 (pop3). You already pick up your email from your ISP's pop3 server so you don't need to use ports 25 and 110. On your webserver, you have a spambot honeypot with thousands of bogus email addresses, all pointing to a domain name that doesn't accept incoming email. Someone has spidered your honeypot and the spam system is now on the verge of containing your bogus email addresses. How do you make sure that they get in there? Anybody collecting email addresses will have a collection of something along the lines of user@domain.com and will need to check that it is a real address (as far as he can tell). To do this, he can:
This might take up days of their time:-) |
POP3 protocol (rfc1939)You can pick up your very own copy of RFC 1939 - Post Office Protocol - Version 3 from http://www.faqs.org/rfcs/rfc1939.html. It will tell you everything you need to know (near enough). One section that is of particular interest is section 9 - Command Summary... Minimal POP3 Commands:valid in the AUTHORISATION state...USER name PASS string QUIT valid in the TRANSACTION state...STAT LIST [msg] RETR msg DELE msg NOOP RSET QUIT Optional POP3 Commands:valid in the AUTHORISATION state...APOP name digest valid in the TRANSACTION state...TOP msg n UIDL [msg] POP3 Replies:+OK -ERR Note that with the exception of the STAT, LIST, and UIDL commands, the reply given by the POP3 server to any command is significant only to "+OK" and "-ERR". Any text occurring after this reply may be ignored by the client. The server starts a session in the authorisation state and all we have to recognise is 'USER name', 'PASS string' and 'QUIT'. However, we can have some fun by issuing additional information over an above the required +OK and -ERR in that we can do apparently insecure things like send additional information such as if a user is verified, but their password fails, we can say that that is what happened (it is advised that merely a +OK is sent on receipt of a USER regardless of whether the user exists and that the PASS is required before any potentially diagnostic information is sent - limiting it to something along the lines of '-ERR the USER/PASSWORD combination failed' but we can let a bit more of the cat out of the bag by telling them that the user is a valid one and that the password was wrong (possibly telling them that the user is valid after the USER command)). Even if we never allow them access to a particular imaginary account, we can still occupy them with perturbed feedback: for example... +OK POP3 server ready 23415.1096045378@pop.domain.com USER john123 +OK john123 is a valid account on this server PASS street-lamp -ERR Password street-limp incorrect By returning an error in their password, we can get them to type it again., wasting some more time - those proxy servers can be a bit unreliable. There are more strategies for wasting time such as giving them long delays (only a few seconds, maybe five to fifteen - it is a busy server after all) throwing them off after only three guesses (mail clients will drop the connection if you send them an error and present the user with the error message and another opportunity to enter a password). In effect, this is like playing a game over the Internet only instead of somebody playing a machine that it pretending to be a human, it is somebody pretending to use a mail client to access a valid POP3 account on a server that is pretending to be a valid but vulnerable POP3 server. As the account does not exist (and never could) the user cannot have any valid reason for trying to get into the account. If you make it easy for them to start the next game, they will stay with it (if you have ever played Frozen Bubble [http://www.frozen-bubble.org/], you will know what I am talking about). Having lost that round, they will have some information to allow them more success (apparently) in the next round. |
xinetd Super-ServerThe eXtended InterNET services Daemon is a super server that can look after a number of connections without overloading the system. It is controlled from the configuration files (each with their standard service name in /etc/xinetd.d (xinetd.directory). Paraphrasing the man page... xinetd starts programs that provide Internet services. Instead of having such servers started at system initialization time and then remain dormant until a connection request arrives, xinetd is the only daemon process started - it instead listens on all service ports for the services listed in its configuration file - when a request comes in, xinetd starts the appropriate server. For our POP3 server, we need to have a file called pop in /etc/xinetd.d and its contents look like this... # default: on
#
# POP3 honeypot
service pop3
{
socket_type = stream
protocol = tcp
wait = no
user = root
server = /usr/local/etc/nopop
log_type = FILE /var/log/pophp/nopopx 2048 2100
log_on_success = PID HOST
log_on_failure = PID HOST
instances = 10
bind = 10.1.2.3
}
By limiting the number of processes to 10 (you could make it as many as you wanted if you have enough memory - get one instance working, see just how much memory it does take up and work out how many you can afford) we are preventing a DoS attack on the system that could be achieved by opening up thousands of sessions thus taking a lot of memory. Note that each session that is started creates a record line in the nopopx file (in this case) so that if you think you are being attacked, you can see which IPs are doing it and get onto their abuse line whilst they are in the act. By binding it to a particular port, we can make it listen only on that port. The advantage of this is not that great with port 110 but if we had an smtp server that we wanted to run as a tarpit on a particular interface and also used our own smtp MTA (say sendmail) which also looks for port 25, for handling our own outgoing mail traffic, we can bind our tarpit to the external interface (using a configuration file like this but for smtp) and let sendmail grab all of the other interfaces. That way, incoming attempts to connect to port 25 will be met with a tarpit and attempts to post mail to port 25 (and therefore to sendmail) either on 127.0.0.1 (local host) or internal interfaces (such as from other machines on the LAN) will get sendmail and work as normal. |
Perl Basics (very)Perl is like many languages in that it has different types of variables and control structures as well as in and out. It is the cross-platform nature of Perl that makes it worth learning (you can get it to work on virtually any platform) and the fact that you can do just about anything with it. The main type of variable is the scalar variable which starts with a $ as in $variable. This can hold strings or numbers of any length (up to the limits of your memory). By allowing you to do this, you can treat data in a more flexible way that does not fall victim to some of the pitfalls that C and other languages have for example, it does not use null-terminated strings. Each line that has a line following it must have a semicolon (;) at the end of the code as in $variable = 6.3; Comments are preceded with a hash mark (#). # The following procedure does this, # that and the other... The first line of a Perl file tells the system that it is a Perl file and where to look for Perl, ie... #!/usr/bin/perl Also, Perl uses STDIN, STDOUT and STDERR so it is all redirectable which means that you can write your code, testing it on the command line, set it up as a server and test it with telnet (on that port) and then use it as a live server without having to alter the code at all. |
Perl spam-tarpit POP3 ServerThere are going to be two types of user for this:
You can modify the Perl script to add any functionality you like - supplying bogus emails full of interesting details about things that are top secret or full of other 'mailing list' email addresses - the sky is the limit. Some things that you will have to do though is waste their time, their resources and have just the right balance of failure and futility with success (whatever that is :-). This is the basic flowchart (click on it to open up a large version in a fresh browser window)...
You can see the whole file by looking on the SuperDisc but here are the key elements with some explanations... As always the file starts off with... #!/usr/bin/perl Then the subs that need declaring are... sub printnlog ($); ...which sends a string to STDOUT and records it, long with the process id (PID from the variable $$) in the log. Also... In my experience, it is customary to have at least one procedure and/or variable with a German name so here, we declare the procedure schlafzeit (which is literally 'sleep time'). This is called each time something needs to be directed at the user and it reacts according to a variable with another German name $teergrube or 'tarpit'. sub schlafzeit ($); Here, we select STDOUT and make it respond immediately we send anything to it in the following two lines... select(STDOUT); $| = 1; Next, we note the time for the purposes of salting and later accounting. $c_time = substr(localtime, 4, -5); $s_time = time; Following this, we generate the salt string for the hash-based authentication that you would use if you were going to employ the APOP command to send a password in an encrypted form... This is how it is represented to demonstrate the dual-use of the full stop... $salt = "<$$.$s_time".chr(64)."pop.domain.com>"; ...as:
$salt = "<$$.$s_time\@pop.domain.com>"; The @ is escaped because without doing so, it would be used to show that the string following it is in fact the name of an array. Thus, if you had "@bill", it would use (or attempt to use) an array called "@bill". If you use "\@bill" it generates the string; "@bill". Next, we respond... print "+OK POP3 server ready $salt\n"; which sends a string like: +OK POP3 server ready <726.1096045378@pop.domain.com> to the user at the other end, whether it is a mail client or someone with telnet. We now have the time we started all of this and the ball is in the other court, so to speak. While this is going on, we do a few background operations and then wait for the 'thing' at the other end to respond. When we get a response, we look at the time again and, as all we have to go on is the amount of time it has taken them to respond - that is all we can use. If it is a machine, it will be fairly quick as it is automatic but if it is a human, it will take longer to type. We can set a threshold value for our decision which I have nominally set as 3 seconds but you could set this lower if you found that people were logging on with clients consistently quicker (say 2 seconds) and this could differentiate better between people with a client and people pasting a piece of text into telnet. The main program loop happens for as long as the client keeps the connection open. If they enter QUIT, our server will end the session (after an appropriate delay) but if they just press their 'end session key sequence' (normally Ctrl+D or Ctrl+] (or something similar)) once the tarpit checks to see if STDIN has anything else to offer, it will bypass the loop and execute the next command. In the loop, we assess the string and react appropriately. Once the delay has been assessed and teergrube has been set or reset, the input is itself is assessed Here is an example with the QUIT command... /^QUIT/ and do {
# go to sleep if a tarpit
schlafzeit(1);
# quit exists in all states
if ($process_state == 1) {
printnlog "+OK POP3 server pop.domain.com signing off";
} elsif ($process_state == 2) {
printnlog "+OK $user_name POP3 server signing off";
} elsif ($process_state == 3) {
if ($delmessages == 0) {
printnlog "+OK $user_name POP3 server signing off";
} else {
printnlog "+ERR $user_name some deleted messages not removed";
};
} else {
# $process_state = 4
printnlog "+OK $user_name POP3 server signing off";
};
done(0);
next;
};
In the first line the /string/ structure tries to match the string against the input. Before the word QUIT, we have a caret (^) which means that the string that follows, if it has to match, has to be at the beginning of the input. So, /^QUIT/ will only match with QUIT, it will not match with FQUIT or Quit or anything else. Following /^QUIT/, we see an 'and' which, if the first part is true (ie matching the string) runs what follows - the contents of the 'do'. The rest is pretty self-explanatory. In the case of user, we need to compare the string with USER and then a space and then other text thus... /^USER\s+(.*)/ and do {
Finally, we break out of the loop for some reason or another (the client end said QUIT or they got thrown off the system for some reason) and we execute the procedure done(0). At the end, I have put the subroutines but you don't have to - you can put them at the beginning or intersperse them between other parts of the program, making it as legible or illegible as possible. It actually doesn't matter as long as Perl can understand it, it's just that if you make it legible, you will be able to understand it when you come back to it in a few months if you want to change something and you will have to find out how it works. ##### subroutines ###
## push the client mailer into
## schlafie-schlafie land
sub schlafzeit ($) {
#sleepy time
my $sst = shift;
if ($teergrube == 1) {
if ($sst == 1) {
sleep int(rand 5) + 50;
} elsif ($sst == 2) {
sleep int(rand 8) + 45;
} else {
sleep int(rand 7) + 2;
};
} else {
sleep int(rand 5) +3;
};
}
I have used plenty of comments in here to make it easy for you to see what is going on as it is easy for somebody else's code to look like three platefuls of spaghetti. To see the nopop source in another window, click here. To see the source for the open source program (which is included here for completeness) that monitors the system for the existence of nopop running, click here. |
