PC Plus HelpDesk - issue 252
This month, Paul Grosse gives you more insight into
some of the topics dealt with in HelpDesk
|
 |
HelpDesk
Multiple domains on one IP address
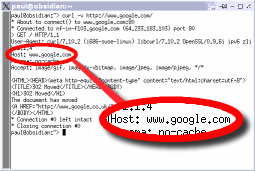
There are several processes going on when you ask for a web page. One of these is that the browser discovers the IP address of the server that it is sending the request to - the DNS provides the IP address. However, when the web browser contacts the web server, there is some extra information passed to it that you will probably not see if you click on document properties in your browser. One of these is that the browser specifies the host that it requires. You can see in the screenshot - which is the output from the 'curl' command - you can see 'Host: www.google.com' on one of the lines in this example. The host line ties up with a virtual host in the server's configuration file (if it is using one) and it is that data that the server sends to your browser. |
 If you ever use
nslookup on Windows or host on a UNIX-like system, you
might have noticed that you can have more than one domain
name on one web server. We have covered a number of times
in HelpDesk how you can create these at the server end
but how does the server actually know? After all, if you
look in the server log for a particular virtual host, all
you will see for the default page is something along the
lines of "GET / HTTP/1.0" or whatever.
If you ever use
nslookup on Windows or host on a UNIX-like system, you
might have noticed that you can have more than one domain
name on one web server. We have covered a number of times
in HelpDesk how you can create these at the server end
but how does the server actually know? After all, if you
look in the server log for a particular virtual host, all
you will see for the default page is something along the
lines of "GET / HTTP/1.0" or whatever.Cascading Style Sheets gone wrong |
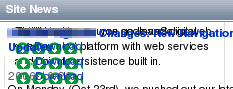 This is
all well and good for most of the time but occasionally,
you encounter a CSS that is not interpreted correctly or
has been designed badly. The sort of effect you get is
all of the columns of text are laid out, over each other,
down the left hand side, image on the wrong place and so
on. This is
all well and good for most of the time but occasionally,
you encounter a CSS that is not interpreted correctly or
has been designed badly. The sort of effect you get is
all of the columns of text are laid out, over each other,
down the left hand side, image on the wrong place and so
on.On the right, you can see a number of examples
where icons blot out the text they are intended to
highlight or place images in the wrong place. |
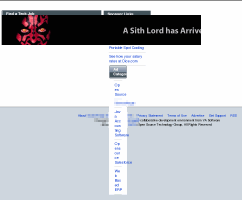 On the
right here, you can see a banner which was meant to go at
the top of the page, actually at the bottom of the page. On the
right here, you can see a banner which was meant to go at
the top of the page, actually at the bottom of the page. |
 You can
see how a menu has been dragged down into a column by the
CSS. You can
see how a menu has been dragged down into a column by the
CSS.This is clearly not a good thing. |
Making LinksYou can create a link that acts just like a file or a directory and if it is on the same partition, it is just like a file or a directory. Suppose you want to get to a directory all of the time but that directory involves going up two directory levels and then down three or four - for example, you might have to go from your home directory to a directory on a mounted partition from another machine. That can be a task and a half if you have to do it several times a day and it is the same one each time. If you could create a link in your home directory that you could click on to take you straight there... If you want to get to /mnts/smb/mc1/work from /home/paul/ then all you have to do is open up a console which should start in your home directory any way and then enter something in the form 'ln [options] [target] [link name]. Supposing we want to call the link 'wk'... ln -s /mnts/smb/mc1/work wk This will create a link in your home directory that you can click on in your file explorer or a name you can cd to from your console.
|
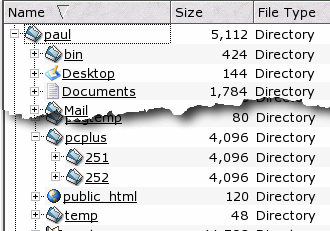 On the right, you can
see my 'pcplus' link in my home directory. On the right, you can
see my 'pcplus' link in my home directory.Regardless of whether it is a symlink or a hard link, the tree display option for the right pane will expand it as though it was in your own directory. In the left pane, it expands in the same way but the link name is displayed in italics. |
Unannounced Email Patches
This virus uses social engineering to try to pass itself off as a genuine email with a patch for 'the problem'. It says 'Mail server report. Our firewall determined the e-mails containing worm copies are being sent from your computer.' (Shouldn't that be '... determined that e-mails ...'.) and as for 'Please install updates for worm elimination and your computer restoring.' ... Then, there is the 'patch' attached with the name 'Update-KB7750-x86.zip'. How could they possibly know what operating system was running on the server? They assume an X86 and looking at the extension, Windows. For all they know, it could be a SparcIIIi processor running OpenBSD. Apart from:
I wouldn't touch it with a barge pole any way because the subject line doesn't conform to the standard I set on my own website. If you see anything like this, you should disregard it completely unless you can confirm with the person who sent it (by a different means, such as by telephone) that it is what they sent (MD5 hash and so on). Another thing you can do is to send it to one of the many anti-virus companies that exist. They will analyse it for viral properties and send you a report back. The example above was sent off to Sophos ( www.sophos.com - go to report a virus) and a reply was received several hours later containing 'Thank you for your email. The file that you sent to us for analysis was a worm, W32/Stratio-AY, further details of which can be found on our web site at http://www.sophos.com/security/analyses/w32stratioay.html '. |
 Be aware that not
every unannounced email patch is good for your system.
Be aware that not
every unannounced email patch is good for your system.Grey-Listing EffectivenessSpam is a nuisance but just how effective is grey-listing as a countermeasure? There are several forms of grey-listing. One of them is to note the IP address of a given connection and then let the server tell it to come back later. The list of such IP addresses is kept in a database for a day or so and if it does come back, it is let through like any normal email. Another, more involved version of grey-listing lets the sender get as far as the 'mail from:' and 'rcpt to:' commands, notes down the two values given as well as the IP address and then stores that in a database before saying 'busy, come back later'. Again, if it comes back matching all of this data, it is let through.
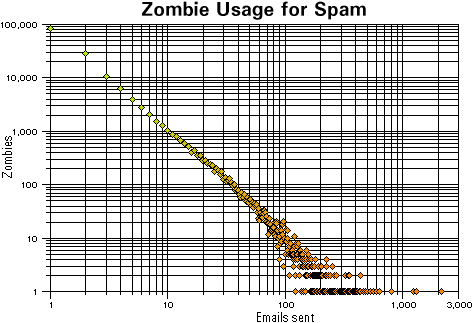
Another problem is that spammers can completely counter grey-listing once and for all just by using standards-compliant zombie mail servers. These keep on trying until the email gets through or the machine is taken out (either by the user disconnecting it (if they are on POTS), shutting it down (maybe they have finished using it) and so on). Any way, the zombie program uses somebody else's electricity so what do the spammers care? So, what proportion of spam do once-only servers account for? The graph (click on it to show the full-sized version in a new window) shows the real-life results from 385,081 attempted spam connections logged by one email tarpit server over a week or so. There were 46,306 distinct IP addresses of which 22,824 sent only one email (the distribution follows a power curve and at the other end, one zombie sent out 1,086 emails). Once-only IPs account for half of them but only around
six per cent of the mail. Note the peaks at 10 and 20
mails. |
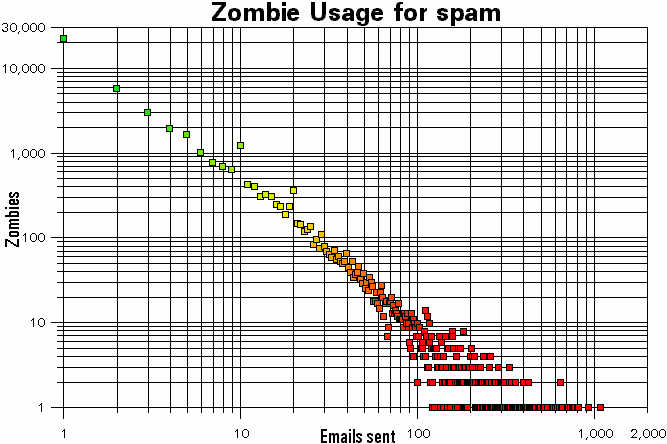
 This graph shows
the real-life results from 644,419 actual spammer
connections logged by the tarpit itself over a period of
around six months. There were 154,773 unique IP addresses
of which 84,869 sent only one email. The proportion of IP
addresses that sent only one email is 55 per cent but
these account for only 13 per cent of the mail. This graph shows
the real-life results from 644,419 actual spammer
connections logged by the tarpit itself over a period of
around six months. There were 154,773 unique IP addresses
of which 84,869 sent only one email. The proportion of IP
addresses that sent only one email is 55 per cent but
these account for only 13 per cent of the mail.So, whilst simple grey-listing would wipe out around 50 per cent of the IPs sending spam, this would account only for roughly six per cent of the spam. Grey-listing can only become less effective as spammers build compliant zombie servers. The best way to combat spammers it to do it proactively by poisoning their address databases with hundreds of thousands of bogus email addresses pointing at dedicated tarpits. Spam filtering is trying to shut the stable door after the horse has bolted. |
Bluetooth Installation
On a train travelling at high speed, you can usually find around half a dozen Bluetooth devices that are 'discoverable' and you will find similar numbers standing at bus stops in the rush hour. I walked around Sheffield city centre at roughly 6pm and found usually around 4 or 5 discoverable devices in queues (of humans, that is) just by using a mobile phone. In the office however, you don't know who is on the other side of your walls - especially in the next business unit. However, there are things that you can do and Linux has the edge over Windows on this (for what it's worth - see Bluetooth Security below). First of all, plug in your USB Bluetooth adapter. You should get a new hardware found dialogue box - click on 'yes' to configure it (you will need root privileges for this). Enable Bluetooth services and under 'Security Manager', make sure that you always ask the user for a PIN. Click on 'Security Options' and if your device supports it, check 'Authentication' and 'Encryption'. Click on 'Finish' and that is it. |
 In the system
tray, you should now the the Bluetooth 'K'. In the system
tray, you should now the the Bluetooth 'K'.Right-click
on it and select 'Open Recent' then 'Recently Seen
Devices'. |
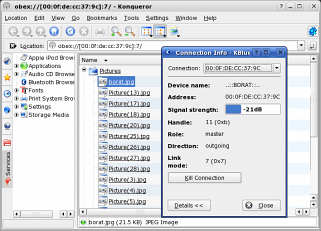 Click on a device
and a browser will open showing the services. Click on a device
and a browser will open showing the services.Here, Obex FTP displays directories on the device and dragging and dropping files into this window will transfer them. In the screenshot on the right, you can also see the signal strength meter as data is being transferred. |
 Many people think that
because Bluetooth has such a small range, it is very
secure - after all, you can see anybody within a five
metre range, can't you?
Many people think that
because Bluetooth has such a small range, it is very
secure - after all, you can see anybody within a five
metre range, can't you?Bluetooth SecurityBluetooth, Bluetooth everywhere - the security is crap. How a bad key selection mechanism undermines Bluetooth security. With Bluetooth's increase in popularity and availability, you can now buy Bluetooth USB dongles in your local shop for around £20. For Windows XP, you need the driver CD although with Vista and Linux, you don't (although you might encounter problems with Vista wanting to install something every time it detects a Bluetooth device). Windows and Linux both allow Bluetooth's encryption but that is not what it seems, thanks to the key selection mechanism. Encryption scrambles up the data content making it difficult - although not impossible - to turn it back into plain text. The power of a particular encryption scheme depends upon two things:
Key lengths are therefore usually quite long and the strength of these is usually a measure of how difficult it is to break the encryption scheme by using brute force. However, key length is actually two processes but because they usually go together, they are normally considered as one. The two processes are:
So, for a key length of 128 bits, you would need to try out 2127 keys on average before finding out the correct one (it is based on the assumption that you will find it half way through your search). 2127 is roughly 170,000,000,000,000,000,000,000,000,000,000,000,000 so the chance of getting the right key is very remote. If you looked at 1,000,000,000 keys per second (you can use a distributed array for this), you would take 4,500,000,000,000 times the age of the Universe to break on average. So, basically, it is impractical. Bluetooth uses 128 bit encryption so that sounds very good. Nice and secure. At least it would be if you had a good key selection mechanism. Although the encryption uses 128-bit keys, the PIN from which each session key is derived only allows 10,000 to be used (0000 to 9999) which effectively makes it 14-bit which is considerably easier to break with a brute force attack (10,000 in binary is 10_0111_0001_0000). It leaves roughly 340,000,000,000,000,000,000,000,000,000,000,000,000 keys never used and therefore nobody ever has to waste their time looking at them. In 2004, it was found that using a Bluetooth packet sniffer, the PIN could be attacked during pairing - the start of a session. However, in 2005, a way was found to do this at any time during the session (you change your address to one of the paired devices and then send out a packet saying 'oops, I forgot the PIN, let's set up a new session' and it starts again although this time, you are monitoring it from the beginning. You sniff the start of the pairing and compare the packets with 10,000 pre-calculated packets to get the one that uses the right PIN). Using a Pentium-IV computer, the session keys can be broken in just 60ms. So, what about distance? In 2005 in London, a microwave tube device was demonstrated that sniffed Bluetooth at a distance of between half and one mile. You can make your own and with a wavelength of just 12cm, you could use a home-made parabolic reflector. So, if you want to be really secure when you use Bluetooth, don't use it within 30 light years of Jodrell Bank or Arecibo. As these units are easy to plug in, take the thing out when you aren't using it. |
Packet Anatomy
The model consists of a series of seven layers with the physical transport (optical, copper wire, radio and so on) at the bottom and the application at the top although some people would argue that there is an eighth and uncontrollable layer - the end-user. Each layer is oblivious to the layers below and as they all connect with each other in a standard way, it doesn't matter how they change - the session layer on one machine talks to the session layer on the other and doesn't know or care whether you use 10BaseT or 100BaseFx locally or even a mixture of Bluetooth, Ethernet, satellite and optical, half way across the planet. As the data is passed down the layers in the model, some layers add their own header. You can see in the edited screenshot of Ethereal, that the data has a session layer added to it and then the network layer and finally, the datalink layer. Not every layer adds its own header. The datalink layer is used by the network to work out how a packet will be routed across a subnet from source to router, router to router, router to destination as applicable and will change at each step (the MAC addresses will be different). The network layer is used between the source and the destination and allows the layer below it to choose a route. The session layer controls how the packets are transmitted between source and destination and the data is what is fed in at one end and appears at the other. You can see that as you go up the layers from the datalink to the data, the steps get bigger until at the data is the smallest unit (for the browser, a web page is the smallest unit and can be comprised of several sets of data - images, text and so on). If you are going to find out what is really going on, you'll need a professional quality packet sniffer and at a cost of nothing, Ethereal has the quality and the price for everybody. Basically, Ethereal is a packet sniffer that can be used to analyse what is really happening on your network. Like many open source programs, it runs on Windows, Linux, *BSD, Solaris (Intel/Sparc), OS X, BeOS, UNIX and so on. To get to know it, start off by having a play. Capture some traffic - this can either be traffic to or from the machine you are working on or, you can have Ethereal use your network card in what is called 'promiscuous mode' whereby it captures traffic on the physical subnet it is on, regardless of where it is going. You can see in the screenshot that Ethereal's screen is divided up into three main areas:
The middle window displays an expandable tree with lower branches for:
|
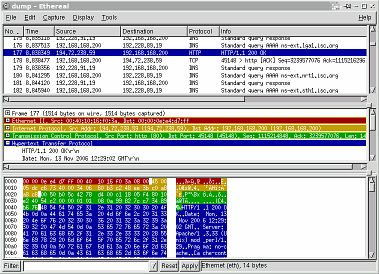 The OSI (Open Systems
Interconnection) model defines a set of layers that allow
applications on one system to talk to applications on
another regardless of how they are connected.
The OSI (Open Systems
Interconnection) model defines a set of layers that allow
applications on one system to talk to applications on
another regardless of how they are connected.Internet Uptime from Packet Headers
The question is, how can it do this and can you do this yourself? The uptime for a particular machine exists at quite a
low level - it is just the irq value for the timer.
Whilst earlier versions of Windows used an interrupt
frequency of 18.2Hz (55ms period), many systems now run
at 100, 250 or 1000Hz. Some systems even change as their
work load changes so only those with stable timer
frequencies are of any user here. So, where are these
timer values and where are they? |
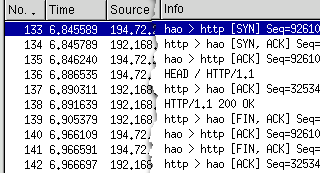 If you are lucky
enough to have a copy of Ethereal (see above), you will
be able to see the packet exchanges that happen when you
download a web page. If you are lucky
enough to have a copy of Ethereal (see above), you will
be able to see the packet exchanges that happen when you
download a web page.If you look at the snippet of a screenshot on the right, you will see that it is one of Netcraft's server contacting my server. Let's see how long it has been up. As always, the first packet is a 'SYN' packet, sent
out by Netcraft and in return, a 'SYN, ACK' packet is
sent out by the server. |
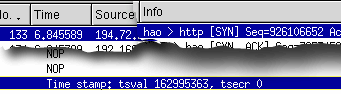 If you expand the TCP
section of the packet and then 'Options', you will see a
section called 'Time stamp'. Note that with certion
server/browser combinations, you might not see this
information. However, when you do, you will see values
for 'tsval' and 'tsecr'. Here, Netcraft has sent a tsval
(this is the lower 32 bits of the server's timer
interrupt counter and on its own, is not a great deal of
value) of 162995363. If you expand the TCP
section of the packet and then 'Options', you will see a
section called 'Time stamp'. Note that with certion
server/browser combinations, you might not see this
information. However, when you do, you will see values
for 'tsval' and 'tsecr'. Here, Netcraft has sent a tsval
(this is the lower 32 bits of the server's timer
interrupt counter and on its own, is not a great deal of
value) of 162995363.Also, note this packet's time (all
six figures after the decimal point). This has the value
of 6.845589 seconds from the beginning of the sample. |
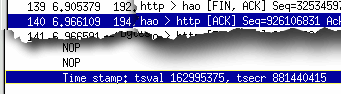 Now, let's look at the
tsval from Netcraft at the end of the session. Packet 140
is from there and has a tsval of 162995375 with a packet
time of 6.966109 seconds. Now, let's look at the
tsval from Netcraft at the end of the session. Packet 140
is from there and has a tsval of 162995375 with a packet
time of 6.966109 seconds. |
| Now for a bit of maths. Take one time from the other and you get 0.120520 seconds (Delta-T). If we take one count from the other, we get 12 interrupts (Delta-I). If we divide Delta-I by Delta-T, we get 99.6 interrupt cycles per second for Netcraft's server. Clearly, there is a potential problem with latency on the line and if this is different between the packets then the timing can be out by quite a bit. To remedy that, just repeat the process by taking samples from several exchanges over, say, a minute and use the count from early on in the session and one from towards the end of it. 99.6 equates to 100 interrupt cycles so we can assume 100 for the purposes of this exercise. Finally, divide tsval (162995375) by the interrupt rate to get the uptime in seconds. This equates to 1629954 seconds or 452 hours or 18 days. So, does this mean that it has been up for 18 days? It might well do. However, one thing to remember is that these are the lower 32 bits of the timer counter and this will cycle back to 00000000 once it has got to ffffffff. Taking this into account, it could be that the machine has been up for 18 day plus any multiple of 497 days, 2 hours, 27 minutes and 52.96 seconds. Note that in addition to the tsval in packet 140, you can also see tsecr which has a value of 881440415 for my computer. It also runs at 100 interrupts per second so work out how long that has been up. (Also, the timer now says 1012245146 so you can see how long it has been between me taking that screenshot and finishing this work for the SuperDVD). If you are going to do several downloads to get times over a longer period, beware of sites that use a pool of servers. Note that you can do this with a web browser on your machine and just look at the returning values in the [SYN ACK] and [FIN ACK] packets from the packet sniffer. |
 Netcraft (
Netcraft (Packet Fragmentation Offset Data Overwrite Vulnerabilities
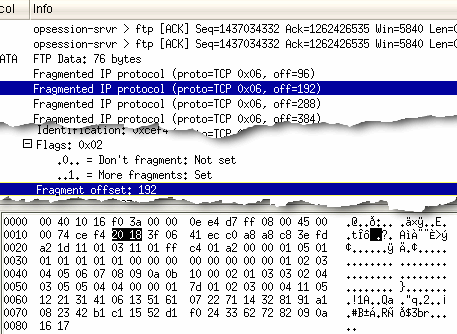
You can see in the screenshot from Ethereal on the right that the offsets are all multiples of eight bytes - this is because there is limited space available in the header and an offset up to 0x10000 - 8 needs to be achievable. So, the packets are split up and at the other end, they are received and reassembled so that the end of one fragment has the beginning of the next packet fragment joined to it. Well, it does if we are all honest. But if we are not,
this is where firewalls come into the picture... |
| You can walk into a high-street shop and buy a router
that claims to have a NAT firewall. NAT is simply Network
Address Translation so an external IP address is mapped
to an internal network address - 1.2.3.4 on the Internet
would map to 192.168.12.15 on your LAN for example.
However, NAT is not a firewall in the proper sense of the
word. A short history lesson... First generation firewalls (Packet Filters) look at the packet header and are very quick. Traffic is filtered according to a set of rules and packets that pass remain unchanged. However, it is easy to spoof the packet header and break through because the data is unchecked. Second generation firewalls (Application Layer Gateways) take a whole stream and reassemble the data at the firewall. If the data conforms to the rules, new packets are built and passed on (therefore fragmented packets are passed on reformed according to their new MTU). However, whilst this has the advantage that none of a stream that is rejected gets through, it takes more processing and adds some latency. Third generation firewalls look at the state information in the headers at a number of layers in the OSI stack, comparing them to a set of rules and is essentially a variant of the packet filter. This is SMLI (Stateful, Multi-Layer Inspection) and is faster than Application Layer Gateways because it only looks at the data content when it is told to (such as with HTTP). SPI (Stateful Packet Inspection) is based on SMLI. However, being packet filters, they can be spoofed.
However, when the browser assembles the stream, the offsets make sure that data is overwritten by subsequent packets thus building contentious content within the buffer before the browser gets it. Application Layer Gateways filter this out and none of it ever gets to the browser. Note also that whilst real-life packet fragment offsets are multiples of eight, this is done here to illustrate the principle of overwriting packets in the buffer. Note that you could also send true end-to-end fragments that are anything down to 8 bytes long and because html uses white space, you could send 01234567 <head><s cript ><!-- fu nction and so on. However, desktop firewalls (Windows Application Firewall) are not the same as Application Layer Gateways. Microsoft uses the term 'Application' because it looks at network sockets from each application - it can do this because it runs on the same machine but it is still just a packet filter and not to be confused with an Application Layer Gateway. Whilst a desktop firewall might sound more secure, running a firewall on a machine used for other things with a hostile network connection is dangerous because there are vulnerabilities introduced by programs working and interacting on the same machine. If you have the money, I would recommend using a hardware firewall of some sort or at least using a software firewall on a dedicated, small machine (this is not a desktop firewall but a proper firewall on a machine with two NICs). However NAT does not a firewall make. |
 If you have two
network segments and the MTU (Maximum Transmission Unit)
is smaller on one than the other, you are going to get
packets fragmented. If your MTU is 1500 on one subnet and
only 150 on the other, the packets that are 1500 long
will be broken down so that they will fit the 150 limit.
The OSI layers that deal with this so that they can build
up the packets to the way that they should be at the
other end and in order to effect this, they have a packet
offset.
If you have two
network segments and the MTU (Maximum Transmission Unit)
is smaller on one than the other, you are going to get
packets fragmented. If your MTU is 1500 on one subnet and
only 150 on the other, the packets that are 1500 long
will be broken down so that they will fit the 150 limit.
The OSI layers that deal with this so that they can build
up the packets to the way that they should be at the
other end and in order to effect this, they have a packet
offset.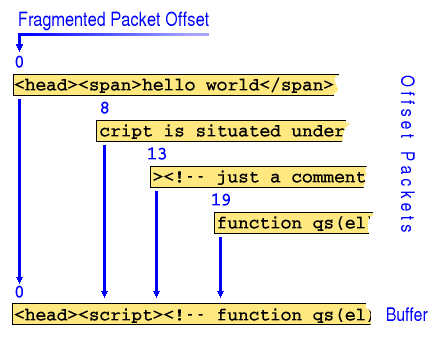 You can see in the
diagram on the right that if you create a stream that
looks fragmented, they will get through because on their
own, none of them has any contentious content (in this
example, scripting.).
You can see in the
diagram on the right that if you create a stream that
looks fragmented, they will get through because on their
own, none of them has any contentious content (in this
example, scripting.).
|
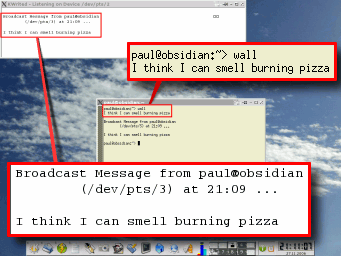 Messages to Other
Users
Messages to Other
UsersQuality Loss from Windows Image Viewer Rotation
Unfortunately, there are a number of things wrong with doing this...
In other words, it messes up your image and overwrites
your original. |
 It's not just Windows
Explorer that does it either. It's not just Windows
Explorer that does it either.This phenomenon is well
documented in the image viewer as well. 'Just click here
to add a little entropy to your image' it should say. |
 In the photograph on
the right, which is of the RAF memorial in London, I have
taken a shot rotated it and reduced it down (effectively
antialiassing out any JPEG errors in the original) so
that it was on its side. I then saved it as a JPEG image
- knowing that any artefacts in there are solely a result
of the JPEG compression used to create the file. In the photograph on
the right, which is of the RAF memorial in London, I have
taken a shot rotated it and reduced it down (effectively
antialiassing out any JPEG errors in the original) so
that it was on its side. I then saved it as a JPEG image
- knowing that any artefacts in there are solely a result
of the JPEG compression used to create the file.I then made a copy of the file (as opposed to just saved another one) so that I had two copies of the original. I then rotated one of them using Windows Explorer in Vista. This overwrote the image. I then loaded both of the images back into the image processor, rotated the one that had not been viewed and rotated so now, I had two copies of the image loaded into the image processor - one that had been saved as JPEG then been rotated and re-saved; and one that had only been saved as JPEG. Next, I took one image away from the other and vice versa. Then, I expanded the density ranges up to full and
added the two images together. |
 The total density
range of errors was 6 units (= +/-3) which doesn't sound
a lot but that was doing it only once. The total density
range of errors was 6 units (= +/-3) which doesn't sound
a lot but that was doing it only once.On the right, you can see where the errors are distributed - it is (very) roughly where you have a change in density such as the corner of the monument for example. This image takes the density-expanded error image and superimposes it on the original. If you mess around with an image a lot, this can become noticeable. So, whilst JPEG performs a good role in reducing image size whilst maintaining a general feel for an image, it is still a lossy compression and therefore only really good for 'exporting' to finished images. If you want a good, non-lossy image format for messing around with then PNG is far better. Certainly, rotating an image in a viewer that overwrites your original is detrimental to your image if you use a lossy compression. |
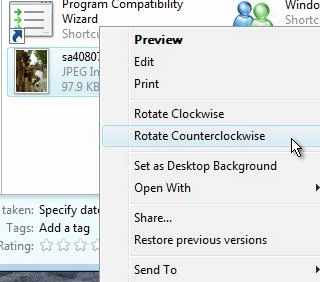 In Windows Explorer
in Vista and in the image viewer in XP, you can rotate an
image through 90 degrees and it saves the image in its
new orientation for you. This is especially handy if you
have taken a picture with the camera on its side and need
to rotate it to get it the right way around again.
In Windows Explorer
in Vista and in the image viewer in XP, you can rotate an
image through 90 degrees and it saves the image in its
new orientation for you. This is especially handy if you
have taken a picture with the camera on its side and need
to rotate it to get it the right way around again.Mebi or Mega?Just when you thought it was safe to buy a hard drive, there's a new(ish) prefix on the block - Giga or Gibi, Mega or Mebi? We have, up until recently known that if we buy what the shop calls a '250GB' hard drive, its capacity will be closer to 250,000,000,000 bytes than the 268,435,456,000 that we would rather it have - of course, that would be just over 7 per cent larger and we're not likely to see anything that is not to the shop's advantage now, are we? Believe it or not, as far back as 1999, the International Electro-technical Commission (IEC) decided that it would make its own contribution to the already confused world of computing-based, pseudo-SI prefixes. We all know 'k' (lower-case K only - the upper-case K is a unit of temperature), 'M', 'G' and 'T' and we are just beginning to see 'P' for Peta as drive arrays grow. These prefixes are all based upon the SI prefixes which are derived from powers of 10. In computing, where things are done in base 2, we find that 210 = 1024 which is quite close to 1000 - it is only 2.4 per cent out so it's close enough for Jazz. However, to distinguish between the long-established 1,000 multiplier prefixes and the more-recent computer-based 1,024 prefixes, the IEC replaced the second syllable with 'bi' for binary and add an 'i' to the short prefix so: 'Kilo' becomes 'Kibi' or 'Ki' (note that now there is no ambiguity with Kelvin, it has changed to an uppercase 'K'); 'Mega', 'Mebi' or 'Mi'; and, so on. This has had seven years so far and it has not caught on although it is not difficult to see why this is the case. You should note that this relates to HDD space, memory and other byte-oriented values and thus clock speeds are always expressed using the true SI prefixes such as 2.0GHz. IUPAC (the International Union of Pure and Applied Chemistry) let all of us English speakers down by insisting that sulphur is spelled the American-English way with an 'f' so this is the computer industry having its go at science as well. That'll teach us real scientists not to insist that 'Computer Science' is not a real science. |