PC Plus HelpDesk - issue 264
 |
This month, Paul Grosse gives you more
insight into some of the topics dealt with in HelpDesk.
|
 |
HelpDesk
Old virus infectionsAnti-virus programs seem to spend a lot of time searching for viruses that are so old that they couldn't possibly still be around (could they?). There are thousands of them. You might, of course ask yourself if this is a waste of time? Although there are many tens of thousands of viruses that are searched for that haven't seen light of day (or the inside of a computer) for years, there can always be a comeback. Whilst we hear regular, although thankfully, infrequent reports of viruses infecting unlikely devices such as SatNav units, new hard drives and personal stereos, there was recently an infection of a batch of laptops for the German and Danish markets that were pre-installed with Microsoft Vista Home Premium and a copy of the 'Stoned.Angelina' virus. The interesting thing about 'Stoned.Angelina' is that it is a boot sector virus that requires a DOS formatted floppy disk to propagate and, if that wasn't enough, it dates back to November 1994. So, whilst it might seem like a waste of time, your scanner does need to know about historical viruses as well as new ones. Stoned.Angelina might be pushing a Zimmer frame around but it still has life in it yet (but not as we know it). |
|
 World map clock
World map clockFont typesIn Linux or BSD, all you need to do to install a font is to open up the Konqueror file browser and in the left pane, select the 'Services' tab and then expand the 'Fonts' line.
You will be prompted once for the root password and it
will install. If you decide to install another (or a
whole load of them by highlighting all you need and
dropping them all in there), you do this within a certain
time, you will not be prompted for the password again. |
 Linux and the BSDs accept a number of
different types of fonts that include: Truetype
(including UTF-8); PostScript Type 1; PCF Bitmap;
OpenType; and, so on. Linux and the BSDs accept a number of
different types of fonts that include: Truetype
(including UTF-8); PostScript Type 1; PCF Bitmap;
OpenType; and, so on. |
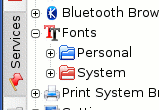 To install
a font system-wide, click on the 'System' folder icon
(right) and then drag your font from your desktop or
another file browser and drop it there.
To install
a font system-wide, click on the 'System' folder icon
(right) and then drag your font from your desktop or
another file browser and drop it there.
|
 Global ad blocking
Global ad blocking
|
 Checking link status
Checking link statusNon-ASCII websitesIt doesn't matter if you've been asked to build a website in Punjabi or want to do some other work in another non-Roman text, the issues here apply to just about any non-European language. So, just to illustrate a point (and for the reason that I happen to be a bit more familiar with it than other texts), we'll use Punjabi (aka Panjabi*) as an example. The issues are:
First of all, even though Punjabi has its own text (Gurmukhi), you might ask why can't it be translated into Roman text any way? The answer has a number of parts:
So, whilst it is possible, it won't mean as much as it
could. |
Inputting text
Inputting this correctly needs knowledge of the important differences between the more confusing glyphs - you don't want to end up typing the wrong character, simply because you didn't understand that two characters that looked very similar are actually quite different.. Knowing how to type it is another matter and for this,
you need to have the purpose of your typing established. |
 Some
fonts produce good characters for typesetting - the
'AmrLipi', and 'Anmol' families of fonts which are free
on the web. Using them to produce PDFs or graphics
doesn't represent a problem. Some
fonts produce good characters for typesetting - the
'AmrLipi', and 'Anmol' families of fonts which are free
on the web. Using them to produce PDFs or graphics
doesn't represent a problem.In the image on the right, the fonts are used graphically so it doesn't really matter how they were produced. Whether they were hand-written, typed using a ASCII-mapped font or a UTF-8 font is of no consequence because that data is not passed onto the user - only the shapes of the letters (here, the letters' outlines were extended on an underlying layer and flooded with white, then a similar process with a smaller amount of black, and then they were drop-shadowed. The letters were then filled with a gradient made from light and dark samples from the image itself). This was all done on The GIMP. The words are actually English and say '#### fruit teas. Hand picked from Yorkshire hedgerows.' However, some of these fonts map into the normal ASCII character range so using them in web pages makes search engines see the body text as garbage. For the Internet, you need to use a Unicode font. Saab
( http://guca.sourceforge.net/typography/fonts/saab/
) is one such font and it is free. Just drop it into your
fonts directory or use the font installer. On Windows and
Linux, add another language to your keyboard (Input
Languages) and when you activate it, the keyboard maps to
the relevant utf-8 range. |
Doing so correctly
You can input text using this interface by clicking on the keys. It works reasonably well apart from two things:
|
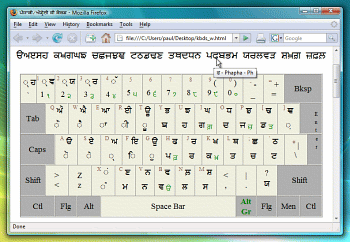
 This is an area of it blown up three times.
You can see that many of the characters are difficult to
read. This is an area of it blown up three times.
You can see that many of the characters are difficult to
read.Also, the area of the keys is quite small, making it difficult to do with a mouse. It is a bit better with a tracker ball but still slow. |
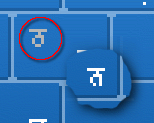 There is also plenty of opportunity for
confusion. On the right, in the red circle is Thatha, the
letter than sounds like 'th'. You can compare this with
'Nana' ('N', inset) and see that there are only two
pixels different (or, looking at it another way, one of
the pixels has moved by one square). There is also plenty of opportunity for
confusion. On the right, in the red circle is Thatha, the
letter than sounds like 'th'. You can compare this with
'Nana' ('N', inset) and see that there are only two
pixels different (or, looking at it another way, one of
the pixels has moved by one square). |
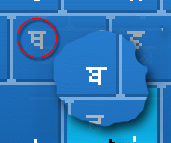 Here is another example - one that is even
more difficult to see. In the circle is Thatha (Th - yes,
there are two, along with four characters that would be
described in the Roman alphabet as 'D', two 'T's and so
on - think tongue position) and inset is Baba (B). Again,
only one pixel moved and it is not obvious if you don't
know what to look for or, if your eyes aren't too
perfect. Here is another example - one that is even
more difficult to see. In the circle is Thatha (Th - yes,
there are two, along with four characters that would be
described in the Roman alphabet as 'D', two 'T's and so
on - think tongue position) and inset is Baba (B). Again,
only one pixel moved and it is not obvious if you don't
know what to look for or, if your eyes aren't too
perfect. |
|
 is rather difficult and time consuming") There
are 35 main letters in the Gurmukhi alphabet (the top
line in the screenshot). Add in another six, an extra
nine vowel sounds and half a dozen or so other signs and
you are getting the idea.
There
are 35 main letters in the Gurmukhi alphabet (the top
line in the screenshot). Add in another six, an extra
nine vowel sounds and half a dozen or so other signs and
you are getting the idea.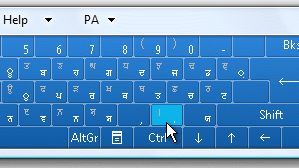 Windows
lets you use the Tablet PC Input Panel displaying the key
mappings but using this is rather difficult and time
consuming because the display is too small. On the right,
you can see part of it at actual size.
Windows
lets you use the Tablet PC Input Panel displaying the key
mappings but using this is rather difficult and time
consuming because the display is too small. On the right,
you can see part of it at actual size.
|
 You can see this with the example on the
right (the source will be protected). You can see this with the example on the
right (the source will be protected).In this case the machine that the browser was running on didn't have GurbaniWebThick on it so 'Thathaa' came out as an uppercase 'Q'. Also, if your web pages need to be indexable by search engines and display correctly, you need to use UFT-8 encoding which gives the characters their own character space. There are two ways of doing this:
One problem with using typed characters (ie, they don't use the '&#nnnn;' codes) is that on some browsers, the title text is not represented in the intended text. So, to solve this, you need to include the following line in the <head> section of the page... <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> |
 In addition, alt and title text display
correctly. In addition, alt and title text display
correctly. |
 If you click here,
you can load a keyboard mapping page that has mixed
English and Gurmukhi scripts - the latter being both in
the direct and the escaped formats. If you click here,
you can load a keyboard mapping page that has mixed
English and Gurmukhi scripts - the latter being both in
the direct and the escaped formats.You can use that web page as a keyboard layout and, if you want to see it bigger, just make the browser text bigger. One thing you might find is that the Rara (J) has the other Rara (AltGr [ ) on the web page on some systems and Iri is a shift-B. This is because the phonetic layout is not entirely standardised yet. All you have to do is to open up notepad or KWrite and
press each key to check that the mapping is correct.
Below the keyboard layout on that web page are the
mappings for all of the characters in the Gurmukhi range,
along with their HTML escape sequences so, if you want to
modify the layout, you can use those sequences - all of
the hard work has already been done for you by laying it
out. If you need to change any, it should be no more than
one or two characters. |
 An alternative is that you take a real
keyboard and, using a 0.5mm - 0.7mm permanent marker (the
type you would use to write on CDRs), write the
characters on them yourself. An alternative is that you take a real
keyboard and, using a 0.5mm - 0.7mm permanent marker (the
type you would use to write on CDRs), write the
characters on them yourself.You can do this fairly easily...
The keyboard in the photograph is used on a Windows and UNIX system so the Bindi and Tippi are reversed and there are the extra shift number patterns for the haha, wawa, (yaya ?) rara at the bottom and the adhikk. On Windows, the top row, Ikk, Doh, Tinn, Charr and so on are accessed with the [Ctrl] key modifier (the normal Roman numbers appear without this modifier key) whereas, on KDE, Ikk, Doh, Tinn ... to ... Atth, Naun and Sifar are accessible without modifiers (if you want the Roman versions, use the number pad instead). Using a keyboard like this speeds up typing quite substantially and soon you can learn to touch-type Gurmukhi. That's something to put on your CV. |
 If you really need to make sure that you
know the characters off by heart, you can always produce
some flash cards similar to those in the photograph on
the right so that you can practice identifying them out
of sequence. If you really need to make sure that you
know the characters off by heart, you can always produce
some flash cards similar to those in the photograph on
the right so that you can practice identifying them out
of sequence. |
 Direct UTF-8 encoding
Direct UTF-8 encoding
|
| In many cases, you don't have to write
any Perl at all. All of this can make design changes and
page updates easy. For those who haven't done this, editing web pages is very easy when you have your own web server because you can edit files on the server - no uploading - just use KWrite (or NotePad if you are using Windows) or similar to edit your page, press [Ctrl][S] to save the file and then press [F5] on the browser to refresh the page. If you want to change the value of a variable - say a cellpadding from 2 to 3, you can do so very quickly. You can do this with plain html files just in a browser, without using a server but this is limited if you want to try out something a bit more advanced. You can make life simpler still so that maintaining a site and keeping consistency is very easy. In fact, if you do it the right way, you can re-brand your site just by editing a few, strategically written files. The obvious way of doing this is to use tables - Cascading Style Sheets (CSSs) aren't yet mature enough to be cross-browser /platform consistent and many messy pages with inconsistent rendering and poor content control appear from poor use of CSSs.
The menu cell in this case is 'valign="top"' and 'align="center"' with the menu itself in a nested table within that. Doing this allows it to remain centred over the background image when changing text size in the browser. The body content is kept a respectable distance from the menu simply by using '<blockquote>' tags to bracket the text. A layout like this will survive reasonable text and window re-sizing without breaking - you often see sites that are packed into an 800 or less pixel width block regardless of the text size or that of the browser (something that doesn't look too good on a monitor with 1280x1024 resolution or larger). You can design your page like this, using whatever WYSIWYG designer or text editor you like and then, look inside the html code and see what is going to be consistent between pages and delegate the job of presenting that to some files. By delegating the consistent web parts to other files
in this way, a new page can be created from a simple,
minimal 'template', re-using the web parts so that you
don't have to re-invent the wheel each time you create a
new page or have to edit all of the pages each time you
want to change something that is common to them all. |
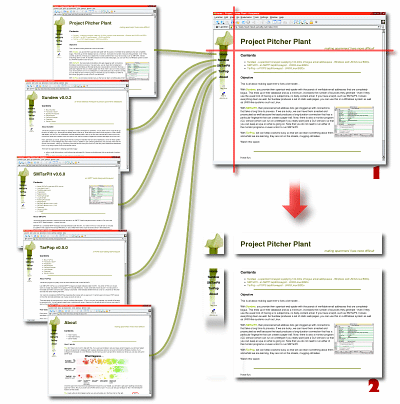 You can see in the diagram on the right how
the master design (1) has been divided up into parts (2)
that need to be general and those that need to be
specific. You can see in the diagram on the right how
the master design (1) has been divided up into parts (2)
that need to be general and those that need to be
specific.Tables work best with designs like these because they hold everything in its place. They also have the flexibility to survive resizes (remember that if someone has poor eyesight, they might have a large monitor with a large font size and having a site taking up half the screen-width with an illegibly small font isn't going to work very well). Tables are laid out in rows from top left to bottom right so here, the top left (pitcher leaf) would be part of a table that never changed. It might have a fragment of code just for a single cell, saved as a file in its own right. The code for the next cell (top right) would be in the page file (there is nothing stopping you from having all but the name in that cell as part of the top left file). Next, you would have a file for the menu cell that runs down the left side. You could have this as static or, if you can write your own Perl, you can make it look at one of the environment variables and find out the name of the page it is serving. With that, you can make the link to the current page dead. Finally, you have the body content. You can, of
course, delegate whatever parts you want to any number of
files and even get Perl to process file content such as
colours or graphics according to what is requested on the
browser's address line. |
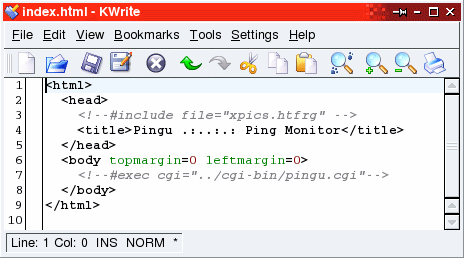 The index.html stub file you can see in the
screen shot shows two of the types of server-side
includes (SSIs) that you can use with Apache. The index.html stub file you can see in the
screen shot shows two of the types of server-side
includes (SSIs) that you can use with Apache.
Note that these page fragments can include other page
fragments. |
| Now that we know how to include web part
files, we can build up a given page that has all of the
consistency saved elsewhere, thus allowing us to keep the
consistent content to a minimum (this reduces the chance
of messing it up as well - something that is important). So, this is what your mypage.shtml file might look like... <html>
<head>
<!--#include file="heading.htf" -->
<title>Paul's Home Page</title>
</head>
<body topmargin=0 leftmargin=0>
<!--#include file="topleft.htf" -->
<p align="center"><font size="+2"
color="#7f7fcf"><b>Paul's Home
Page.</b></font><br><font size="-1"><i>Talk
about food and odd-looking carnivorous
plants</i></font></p>
<!--#include file="menuleft.htf" -->
<!-- body content starts here -->
<!-- body content ends here -->
<!--#include file="footer.htf" -->
</body>
</html>
...where 'heading.htf', 'topleft.htf', 'menuleft.htf' and 'footer.htf' are static html fragments (note, you don't need to have any knowledge of Perl or anything else to write static web parts) that make up the missing bits. These fragments don't have to have whole numbers of cells in them, you can see that the footer.htf file would have the end of the table definition (ie, </table> tag). By saving your page like this, you end up with consistently laid out pages that you can tweak to your heart's content. If you decide that you want to add another item to the menu (or take one out), you just have to edit 'menuleft.htf' and all of the pages will be affected in the same way. The pages don't have to be called '*.htf', you can have any file name you like (or put them anywhere you like within the document root's file structure). If you want to make your menu (or any other part) interactive with the page that is loading it (for example, you want the menus to change for a given page), you can take out that file and turn it into a cgi script (best done in Perl) and change the line in the page from... <!--#include file="menuleft.htf" --> ...to... <!--#exec cgi="/cgi-bin/menuleft.cgi" --> Note that you are taking the static data file out of the document root, turning it into an executable and putting it into the cgi-bin directory. This is purely down to common sense. You should never put executable files in the document root because if somebody managed to place a file there and it was allowed to execute, it could do serious damage. All sensibly configured web servers do not allow executables to run outside the cgi-bin directory. Note that you cannot download the contents of the cgi-bin, you can only retrieve the output of the programs in there when they are run. So, how do we get our web pages to have their contents examined by the server and any directives acted upon, instead of merely copied to the client machine? SSIs need the web server to know when to look inside an HTML file to see if there is anything to process.
With your page-top, breadcrumb, menu and any other bits sorted out and stored as separate files, you can fill your page's stub file with the content from your old site knowing that if you want to change a menu, you can do so with complete consistency. |
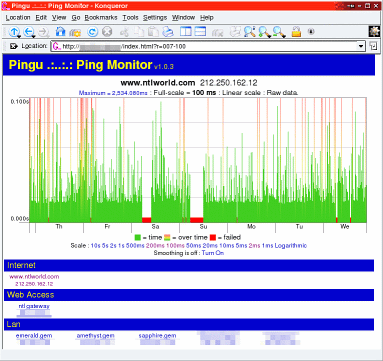 Control your website
Control your website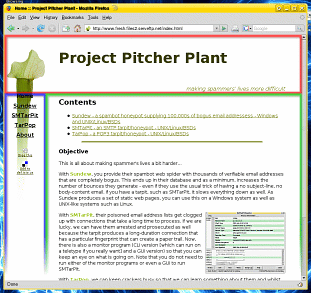 In the
screenshot, you can see how this table-based page
consists of a header (red), a menu down the left hand
side (blue) and then the page content (green). Using SSIs
allows you to create pages or page-creating scripts for
the header and menu sections - you might even want to add
a breadcrumb for more intricate sites. There is nothing
stopping you from adding a categorised section down the
right of the page as well as a footer. Simple, complex -
the choice is yours.
In the
screenshot, you can see how this table-based page
consists of a header (red), a menu down the left hand
side (blue) and then the page content (green). Using SSIs
allows you to create pages or page-creating scripts for
the header and menu sections - you might even want to add
a breadcrumb for more intricate sites. There is nothing
stopping you from adding a categorised section down the
right of the page as well as a footer. Simple, complex -
the choice is yours.